Generative Engine Optimization: the 2026 founder's checklist
Most founders still don't have llms.txt live—here's the exact 12-item checklist to make your site visible to ChatGPT, Perplexity, and every other AI system that's replacing Google search.

Most paid-ads founders we talk to have never heard of llms.txt. A smaller group has heard of it and assumes it's something to do with "later." Meanwhile, AI assistants are actively fielding questions like "best tool to stop wasting money on Google Ads" right now—and the answer they return is whoever showed up in their training data and crawl index. Not whoever has the best product, and not whoever has the most recent funding announcement.
That's the real GEO problem: it's invisible until it's urgent. You don't feel the missing citation the way you feel a broken ad. But the compounding cost is real.
- GEO (Generative Engine Optimization) is the discipline of making your site citable by AI systems—ChatGPT, Perplexity, Claude, Gemini—not just rankable by Google.
- The technical floor is six items: crawlers allowed, sitemap submitted,
llms.txtlive, structured data on every page, Core Web Vitals clean, AI-referrer analytics wired up. - The content floor is six more items: author E-E-A-T signals, FAQ schema, primary-source claims (real numbers, not hedged generalities), topic cluster architecture, outbound citations to authoritative sources, and at least one piece of original research only you can publish.
- AI systems cite content pages, not homepages—every checklist item exists to make individual pages citable.
- The fastest single move: publish
llms.txtat your root today. It takes under an hour and signals intent to every major AI crawler.
The 12-item checklist
We split this into two halves: technical foundation (things that must be in place before content does anything) and content signals (things that determine whether AI systems trust you enough to cite you).
Technical foundation
robots.txtexplicitly allows AI crawlers (GPTBot, PerplexityBot, ClaudeBot, OAI-SearchBot)- XML sitemap generated and submitted to Google Search Console and Bing Webmaster Tools
llms.txtlive at your root domain- Schema.org JSON-LD on every public page (Article, FAQPage, HowTo, or SoftwareApplication as appropriate)
- Core Web Vitals passing (LCP under 2.5s, CLS under 0.1, INP under 200ms)
- AI-referrer analytics tracked separately from organic search
Content signals
- Named author with full E-E-A-T profile (bio, headshot, credentials, social proof)
- FAQPage schema on any page targeting a conversational query
- At least one primary-data claim per post (a real number, a test result, a comparison only you ran)
- Topic cluster architecture: one pillar page per niche, cluster posts that link back to it
- Outbound citations to primary sources (studies, platform docs, not other blog posts)
- At least one piece of original research published per quarter
Current state of AI crawlers
Before you touch robots.txt, know exactly what you're allowing. These are the four crawlers that matter most right now:
| Crawler | Operator | What it fetches | Allow/block directive | Official docs |
|---|---|---|---|---|
| GPTBot | OpenAI | Pages for model training | User-agent: GPTBot | openai.com/gptbot |
| OAI-SearchBot | OpenAI | Pages for ChatGPT live search | User-agent: OAI-SearchBot | openai.com/searchbot |
| PerplexityBot | Perplexity AI | Pages for real-time answer synthesis | User-agent: PerplexityBot | docs.perplexity.ai/guides/bots |
| ClaudeBot | Anthropic | Pages for training and retrieval | User-agent: ClaudeBot | anthropic.com/claude-bot |
GPTBot and OAI-SearchBot are distinct. GPTBot feeds training data; OAI-SearchBot feeds live ChatGPT search results. If your only goal is to appear in current ChatGPT answers (not future model training), OAI-SearchBot is the one that matters today. Allow both unless you have a specific reason not to.
Why each item matters
Items 1–2: crawlability is table stakes. Many Next.js apps go live with a staging robots.txt that blocks all crawlers. If GPTBot can't read your site, you don't exist to ChatGPT—full stop. The sitemap ensures crawlers find every page, not just the ones linked from your homepage.
Item 3: llms.txt. This is the fastest win on the list. It's a plain-text file—similar in spirit to robots.txt but written for language models rather than crawlers—that describes what your product does, who it's for, and where to find the important pages. We shipped ours before we had a blog. It costs one engineering hour and signals to every AI crawler that you've thought about this. The current specification is worth reading before you implement.
Item 4: structured data. Schema.org JSON-LD gives AI systems structured facts about your content without making them parse prose. The FAQPage schema is particularly high-leverage for GEO because it maps directly to the question-answer format AI assistants prefer to cite. We've added Article, FAQPage, HowTo, and ItemList schemas to our core pages—Google's structured data documentation is the primary reference.
Item 5: Core Web Vitals. A slow page that passes all other checks still gets deprioritized by crawlers that factor in page quality. Run npx lighthouse https://yourdomain.com --view before you do anything else.
Item 6: AI-referrer analytics. You can't improve what you don't measure. When AI systems surface a link, they send referrer signals you can track. The main ones to watch: chatgpt.com, perplexity.ai, bing.com (Copilot), and claude.ai. Wire these up as a separate segment in your analytics so you know which pages are actually being cited—without this, GEO work is invisible.
Item 7: named author with E-E-A-T signals. A named author with verifiable credentials—a real bio, a headshot, links to other published work—functions as a trust signal for both Google and LLMs. Google's E-E-A-T guidelines explicitly reward demonstrated experience. For a paid-ads tool, "experience" means you've run ads, not just written about them.
Before publishing anything, ask: "If a researcher were writing a paragraph about this topic, would they cite this specific page over the Wikipedia article or the platform's own docs?" If the answer is no, the page isn't GEO-ready yet. Add a real number, a test result, or a unique framing until the answer is yes.
Item 8: FAQPage schema. Conversational AI queries map almost perfectly to FAQ format. When Perplexity answers "what does AdControlCenter do?" it is, structurally, looking for a question-answer pair it can surface. FAQPage schema makes that easy to find. Every page targeting a conversational query should have it.
Item 9: primary-data claims. Generic content—"negative keywords reduce wasted spend"—is everywhere. AI systems have no reason to cite your version over anyone else's. But "we ran this test on X campaigns and found Y" is a unique claim that can only be attributed back to you. Our competitive advantage here is direct: we sit on a labeled corpus of ads, budget-leak detection patterns, and cross-platform sync data that nobody else has access to. When we publish findings from that corpus, those findings are citable in a way that recycled wisdom is not.
Item 10: topic cluster architecture. AI systems don't just cite individual pages—they build a picture of domain authority across a topic. If you have one good post about Reddit Ads, you might get cited once. If you have a pillar page plus eight cluster posts that interlink, you become the apparent authority on Reddit Ads, and citations compound. We're building three to four pillars, each with eight to twelve cluster posts.
Item 11: outbound citations. It's counterintuitive, but linking out to primary sources—Google's Search Console documentation, Perplexity's crawling guidelines, Schema.org's FAQPage spec—increases your own perceived credibility. It signals that your content is situated in the real information ecosystem, not a closed loop of self-referential marketing.
Item 12: original research, quarterly. One piece of real research per quarter—a data analysis, a test we ran, a corpus we labeled—does more GEO work than twelve generic posts. It creates a primary source. Other people link to primary sources. AI systems cite what other people link to.
How to verify each is in place
Run through this in order. Every item has a direct verification method:
| # | Item | How to verify |
|---|---|---|
| 1 | Crawlers allowed | curl https://yourdomain.com/robots.txt — check for GPTBot, OAI-SearchBot, PerplexityBot, ClaudeBot |
| 2 | Sitemap submitted | Google Search Console → Sitemaps → confirm "Success" status |
| 3 | llms.txt live | curl https://yourdomain.com/llms.txt — should return plain text, not 404 |
| 4 | Structured data | Google's Rich Results Test — run every public page type |
| 5 | Core Web Vitals | npx lighthouse https://yourdomain.com --view |
| 6 | AI-referrer analytics | Filter sessions by referrer containing chatgpt.com, perplexity.ai, bing.com/chat, claude.ai |
| 7 | Author E-E-A-T | Author page has photo, bio, credential claim, and at least one external link to verify identity |
| 8 | FAQPage schema | Rich Results Test → confirm FAQPage detected |
| 9 | Primary data | Every post has at least one claim that begins "when we tested…" or "our data shows…" |
| 10 | Cluster architecture | Every cluster post links to its pillar; pillar links to all cluster posts |
| 11 | Outbound citations | Every post has at minimum two outbound links to primary sources (not blog posts) |
| 12 | Original research | Calendar reminder: one research publish per quarter |
What we still don't know
We'll be direct about the uncertainty here, because anyone who gives you a confident GEO formula right now is overselling.
Citation weighting is opaque. We know AI systems favor primary sources, named authors, and structured data. We don't know the exact weight of any of these signals, and the weights shift when models are retrained. This is fundamentally different from Google SEO, where years of testing have produced reasonably stable heuristics.
Training cutoffs vs. live crawl. ChatGPT answers partly from training data (with a cutoff) and partly from live web search when Search is enabled. Perplexity is almost entirely live crawl. Claude varies by context. Whether your freshly published post gets cited depends heavily on which system the user is asking and whether real-time search is active in that session. Publishing great content today may not show up in ChatGPT answers for months if a user isn't using the Search tool.
The llms.txt standard isn't ratified. It's a reasonable proposal gaining adoption, not an official standard. We've implemented it because the cost is near zero and the upside is real, but we're watching whether major AI systems actually adjust behavior based on it.
Answer Engine Result Pages aren't stable. Perplexity's citation format, ChatGPT's source cards, Google AI Overviews—these interfaces are changing every quarter. Optimizing for the exact current format is less durable than optimizing for the underlying signal: genuine authority on a narrow topic, demonstrated by real data.
What we're most confident about: depth beats breadth, primary data beats opinion, named authors beat anonymous content, and structured data beats unstructured prose. Those signals have been consistent long enough that we're willing to build a content strategy around them.
FAQ
What is GEO and how is it different from SEO?
SEO (Search Engine Optimization) is about ranking in traditional search engines like Google and Bing, where a user sees a list of links and clicks through. GEO (Generative Engine Optimization) is about being cited by AI systems—ChatGPT, Perplexity, Claude, Google AI Overviews—that synthesize an answer directly and may or may not surface a link. The underlying content signals overlap significantly (authority, depth, structured data), but GEO adds requirements SEO doesn't: llms.txt, explicit AI-crawler permissions in robots.txt, FAQPage schema, and a higher bar for primary-source claims.
What is llms.txt and do I need it?
llms.txt is a plain-text file placed at your root domain that describes your site in terms a language model can parse directly—what your product does, who it's for, and where the important pages are. It's modeled on robots.txt but intended for LLMs rather than crawlers. It's not an official standard, but it's gaining adoption and costs under an hour of engineering time to publish. Yes, you should have it.
What's the difference between GPTBot and OAI-SearchBot?
GPTBot fetches pages to feed OpenAI's model training pipeline. OAI-SearchBot fetches pages to power live search results inside ChatGPT when a user has Search enabled. If your goal is to appear in current ChatGPT answers, OAI-SearchBot is the crawler that matters today. Allow both in your robots.txt unless you have a specific legal or competitive reason not to—blocking one while allowing the other is a meaningful distinction.
Does structured data actually help AI systems cite my content?
Our read of the evidence: yes, meaningfully. Schema.org JSON-LD—especially Article, FAQPage, and HowTo schemas—gives AI systems explicit, machine-readable facts that don't require parsing prose. FAQPage schema in particular maps directly to the question-answer format that conversational AI prefers to surface. Google's documentation on structured data is the primary source here.
How do I track whether AI systems are sending traffic to my site?
Filter your analytics by referrer. The main referrers to watch are chatgpt.com, perplexity.ai, bing.com (Copilot), and claude.ai. Set these up as a separate segment or custom channel grouping so you can watch the trend over time. Raw session volume from AI referrers is currently small for most sites, but the growth rate is the signal—and early investment in GEO is precisely when compounding starts.
Can a small site with few backlinks compete in GEO?
More than in traditional SEO. AI systems weight content quality and topical specificity heavily—a narrow, deep answer with a named author and real data can outrank a generic post from a high-DA domain. The practical advice: own one specific topic completely before expanding. One pillar cluster done properly is worth more than ten shallow posts across ten topics.
What's the single highest-leverage GEO action for a founder starting today?
Publish llms.txt, confirm AI crawlers are allowed in robots.txt, and write one piece of content where the central claim is a number only you have. In that order. The first two take under two hours combined. The third is harder—but it's the only durable GEO moat, because it creates something genuinely worth citing.
The hardest part of this checklist isn't any individual item—it's maintaining the discipline to publish primary data instead of opinion. We're building that muscle ourselves. The question worth sitting with: what do you know about your customers' ad performance that nobody else in the world has access to? That's your GEO edge. Publish it.
We build AdControlCenter — AI-powered ad management for anyone running their own ads. We write what we'd want to read: real numbers, no fluff, the things we wish we'd known when we started.
More from the team →Keep reading
All posts →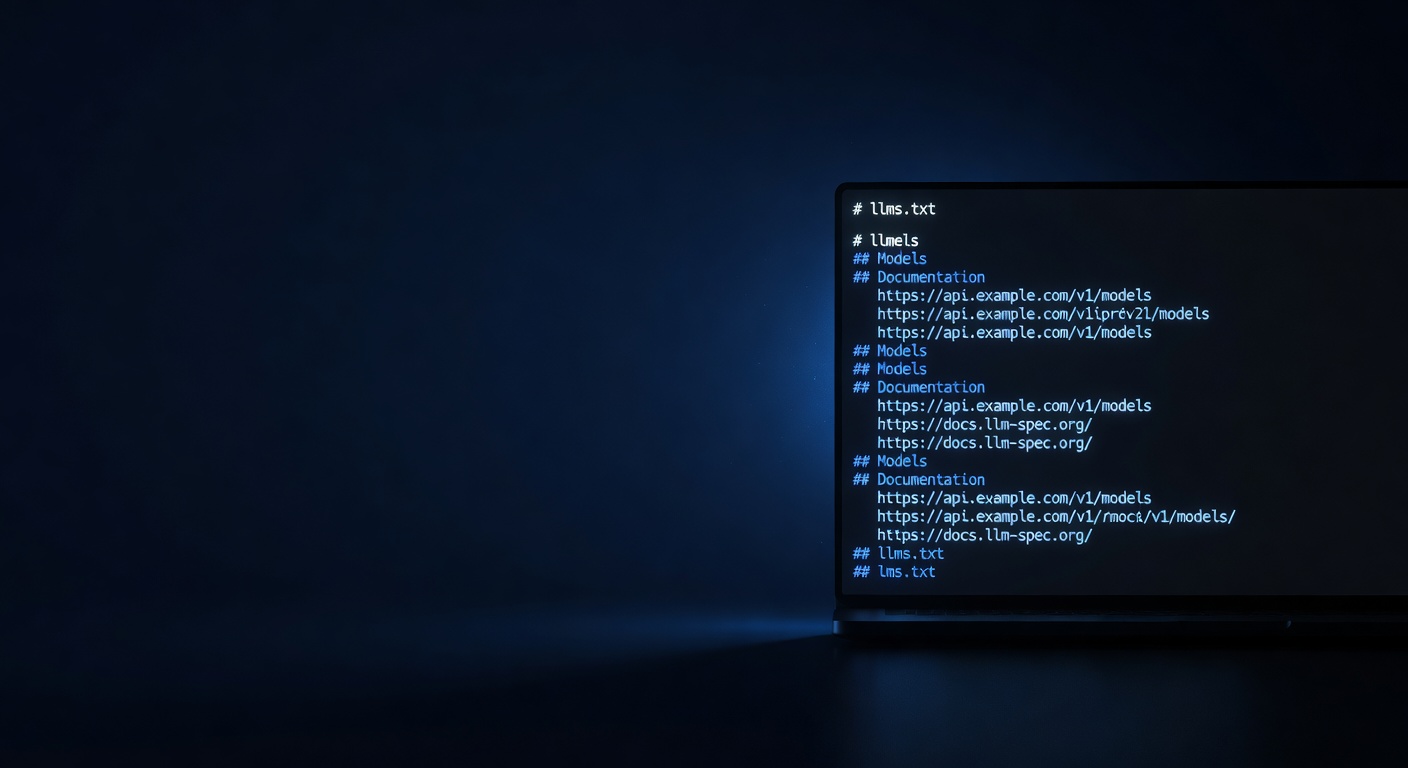
llms.txt: what to put in yours (with a real example)
The two-minute file that tells ChatGPT, Perplexity, and Claude exactly what your product does — and why most sites are getting it wrong.

AEO, GEO, and the Death of Keyword-First SEO Strategy
Keyword rankings are no longer a reliable proxy for business outcomes — here's what AEO and GEO actually change about how you should build content.

Is Your Brand Invisible to AI? How to Show Up Before Rivals Do
AI search engines are already recommending your competitors by name — here's the exact content and signal infrastructure that gets your brand cited instead.